Bỏ MongoDB? PostgreSQL JSONB chứng minh không cần NoSQL để scale
Tác giả: Kim Chính Ân
Đăng nhập để đánh giá bài viết

Câu chuyện về một lần mất dữ liệu khiến tôi phải rời bỏ “schemaless” để quay về với “data integrity” thực sự
Sự cố bắt đầu từ một điều không ai ngờ
Hệ thống của chúng tôi… mất 47 đơn hàng.
Không phải crash. Không phải corrupt. Chỉ đơn giản là biến mất.
Không lỗi. Không cảnh báo. Không log rõ ràng.
Chỉ là khoảng trống — nơi đáng ra phải có 8.400 USD giá trị giao dịch của khách hàng.
MongoDB thậm chí không nhận ra điều đó.
Khoảnh khắc đó, tôi hiểu rằng: chúng tôi đã chọn sai.
“Web Scale” — và những điều chúng ta tự thuyết phục mình tin
6 tháng trước đó, chúng tôi ngồi trong phòng họp với CTO và một kỹ sư backend kỳ cựu lâu năm.
Anh ta nói:
“Database quan hệ không scale được.”
“Schema migration rất đau đớn. Sao không… bỏ luôn schema?”
Nghe hợp lý. Thậm chí rất thuyết phục.
Và thực tế lúc đó:
Startup nào cũng dùng MongoDB
Tutorial nào cũng bắt đầu bằng MongoDB
“Modern stack” gần như đồng nghĩa với NoSQL
Chúng tôi tin rằng mình đang chọn tương lai.
Tuần trăng mật: Khi mọi thứ đều “quá dễ”
Thời gian đầu, MongoDB thật sự tuyệt vời.
Không cần migration. Không cần ALTER TABLE. Không cần tranh cãi kiểu dữ liệu.
Chỉ cần:
db.users.insertOne({
name: "John",
email: "[email protected]",
preferences: {
notifications: true,
darkMode: false
}
})Nhanh. Gọn. Hiệu quả.
Velocity của team tăng vọt. Feature ra liên tục.
Chúng tôi nghĩ: đây chính là tương lai.
Và rồi thực tế bắt đầu lộ diện
1. “Schemaless” chỉ là ảo tưởng
Bạn không hề không có schema.
Bạn vẫn có schema — chỉ là nó nằm rải rác trong code.
Ví dụ:
// file 1
{ email: "[email protected]", age: 25 }
// file 2
{ email: "[email protected]", age: "25" }
// file 3
{ email: "[email protected]", dateOfBirth: "1999-01-01" }Cùng một collection. Ba schema khác nhau.
MongoDB: “Không sao đâu.”
Production: “Toang rồi.”
2. Không có join = dữ liệu bị trùng lặp
MongoDB khuyến khích denormalization.
Nghe thì hay. Nhưng thực tế:
Dữ liệu bị duplicate
Và duplicate → inconsistency
Chúng tôi có user data ở 4 nơi:
users
orders
reviews
analytics
Khi user đổi email?
Chỉ update được một nơi.
Ba nơi còn lại… giữ nguyên.
Kết quả:
“Tại sao email xác nhận đơn hàng vẫn gửi vào email cũ?”
3. Aggregation pipeline: cơn ác mộng JSON
Một query “GROUP BY” đơn giản trong MongoDB:
→ 50 dòng JSON pipeline
Cùng logic đó trong SQL:
→ 10 dòng, đọc được, debug được
Sự khác biệt này chỉ thực sự đau khi:
2 giờ sáng, production đang cháy, và bạn phải debug.
Sự cố khiến chúng tôi tỉnh ngộ
Thứ Sáu, 3:47 PM.
Job xử lý thanh toán đang chạy. ~2000 đơn.
MongoDB replica set elect primary mới.
Ngay giữa lúc ghi dữ liệu.
Không transaction.
Không đảm bảo ACID.
Kết quả:
Thanh toán thành công
Nhưng order record… không tồn tại
47 đơn hàng biến mất.
Chi phí thực tế
8.400 USD phải hoàn lại/ xử lý thủ công
40 giờ điều tra
Mất niềm tin khách hàng
Và rất nhiều áp lực cho team
PostgreSQL + JSONB: sự kết hợp hợp lý
Điều chúng tôi nhận ra:
PostgreSQL đã có JSONB từ năm 2014.
Bạn có:
JSON linh hoạt như MongoDB
Schema khi cần
ACID transaction đầy đủ
Foreign key, constraint
SQL dễ đọc
Ví dụ:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE NOT NULL,
profile JSONB
);Bạn vẫn có flexibility.
Nhưng không mất integrity.
Migration: đau, nhưng đáng
4 tuần migration:
Dual write
Validate dữ liệu
Switch read
Tắt MongoDB
Thách thức:
12 triệu document
Zero downtime
Data cleanup cực kỳ phức tạp
Kết quả sau 6 tháng
Hãy để tôi chỉ cho bạn những con số mà các fanboy MongoDB không muốn nói tới:
Performance:
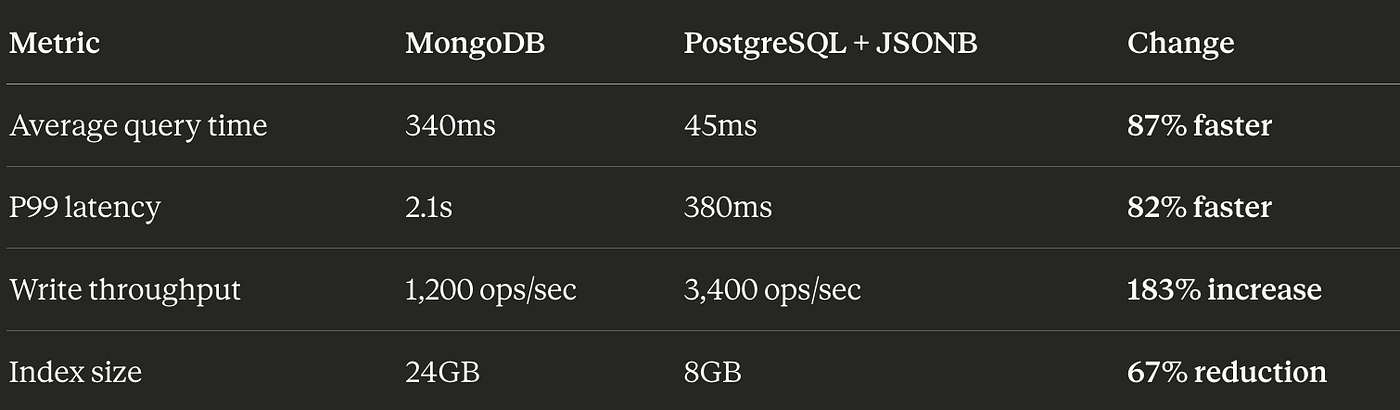
Operational:

Developer Experience:

Chúng tôi có lại:
1. Transaction thực sự
Hoặc tất cả thành công, hoặc không gì xảy ra.
Không còn mất đơn hàng.
2. Constraint bảo vệ dữ liệu
Không thể insert dữ liệu sai.
Không còn “garbage data”.
3. Debug dễ dàng
EXPLAIN ANALYZE
Query planner rõ ràng
Index minh bạch
4. Tooling trưởng thành
PostgreSQL có hệ sinh thái đã được kiểm chứng hàng chục năm.
“Web Scale” có thật không?
Sự thật:
Phần lớn startup không cần scale kiểu MongoDB quảng cáo.
Ví dụ:
Instagram → PostgreSQL
Reddit → PostgreSQL
Spotify → PostgreSQL
Nếu họ dùng được, bạn cũng vậy.
Khi nào MongoDB phù hợp?
Không phải lúc nào MongoDB cũng sai.
Nó hợp khi:
Dữ liệu cực kỳ linh hoạt (IoT, logs)
Không cần consistency mạnh
Document độc lập
Nhưng KHÔNG phù hợp khi:
E-commerce
Tài chính
User system
Bài học quan trọng
Chúng tôi chọn MongoDB vì:
Hype
Trend
“Modern stack”
Chúng tôi chọn PostgreSQL vì:
Trải nghiệm thực tế
Sự cố production
Data integrity
Checklist trước khi chọn database
Hãy tự hỏi:
Bạn có cần transaction không? → gần như luôn là có
Bạn có quan hệ giữa dữ liệu không? → có
Bạn có cần query phức tạp không? → chắc chắn có
Nếu câu trả lời là “có” → hãy bắt đầu với PostgreSQL.
Nếu được làm lại
Tôi sẽ:
Bắt đầu với PostgreSQL
Chỉ thêm NoSQL khi thực sự cần
Test failure scenario từ sớm
Kết luận
MongoDB bán “tốc độ phát triển”.
PostgreSQL mang lại “độ tin cậy”.
Và trong production: Độ tin cậy luôn thắng.
